Visualize how GPU processes are distributed across nodes in distributed LLM training. Configure cluster and parallelism sizes (TP, EP, CP, DP, PP), and see an interactive visualization of process-to-GPU mapping with color-coded communicator groups.
Communicator Basics
In distributed training, GPUs are organized into process groups (communicators). Each group defines a set of GPUs that need to communicate for a specific type of parallelism. A single GPU belongs to multiple communicator groups simultaneously — one for each parallelism dimension.
Rank Mapping Formula
Megatron-LM assigns global ranks using a nested loop where TP is innermost (fastest varying) and PP is outermost (slowest varying):
rank = tp_i + TP × (ep_i + EP × (cp_i + CP × (dp_i + DP × pp_i)))
This means GPUs with consecutive ranks share the same TP group, which is critical because TP requires the highest communication bandwidth (NVLink within a node).
Group Identification
Two GPUs belong to the same communicator group if they share the same indices in all other dimensions. For example, two GPUs are in the same TP group if they have the same (ep_i, cp_i, dp_i, pp_i) but different tp_i.
Collective Operations
Each parallelism dimension uses specific NCCL collective operations:
AllReduce (TP, DP)
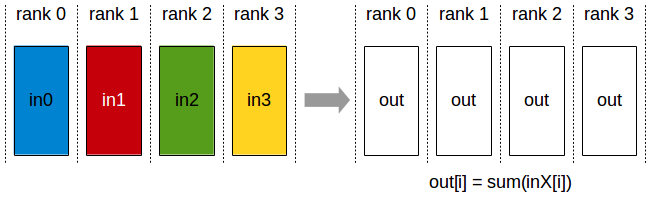
Every rank contributes data and receives the fully reduced result. Used by:
- TP: Synchronize partial activation results after column/row-parallel linear layers (every layer, forward + backward)
- DP: Gradient synchronization across data-parallel replicas (without ZeRO / distributed optimizer)
ReduceScatter (DP with ZeRO)
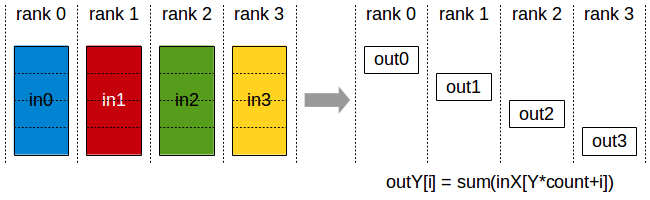
Reduces data and scatters chunks to different ranks. Used by:
- DP with ZeRO/distributed optimizer: Each rank receives only its shard of the reduced gradients
AllGather (DP with ZeRO, TP)
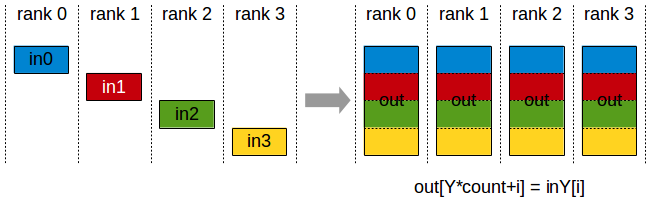
Each rank contributes a chunk; all ranks receive the full concatenated result. Used by:
- DP with ZeRO: Gather full parameters before forward/backward passes
- TP: Column-parallel output gathering
AllToAll (EP)
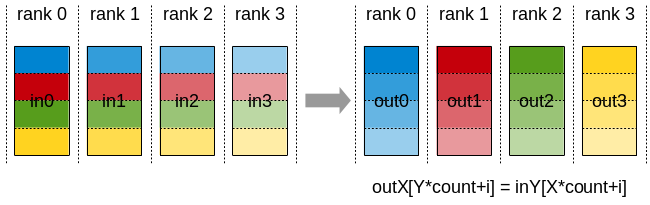
Each rank sends different data to every other rank (personalized exchange). Used by:
- EP: MoE expert routing — dispatch tokens to assigned experts and combine results back
Send/Recv — Point-to-Point (PP)
Pipeline parallelism uses P2P Send/Recv between adjacent pipeline stages. Stage k sends activations to stage k+1 during forward, and stage k+1 sends gradients back to stage k during backward.
Why This Ordering? (TP innermost, PP outermost)
The ordering is determined by communication bandwidth requirements:
| Parallelism | Collective | Frequency | Volume per Op | Bandwidth Need |
|---|---|---|---|---|
| TP | AllReduce | Every layer (fwd+bwd) | O(b × s × h) | Highest |
| EP | AllToAll | Every MoE layer | O(b × s × h × top_k / E) | High |
| CP | P2P Ring + AllGather | Every attention layer | O(b × s × h / CP) | Moderate |
| DP | AllReduce / ReduceScatter | Once per micro-step | O(params), overlapped | Low (overlapped) |
| PP | P2P Send/Recv | Per micro-batch boundary | O(b × s × h) per boundary | Lowest |
Key Insight
- TP communicates EVERY layer → needs the highest total bandwidth → must use NVLink (intra-node, 900 GB/s on H100)
- EP communicates every MoE layer → high bandwidth → typically intra-node or single-hop inter-node
- DP communicates ONCE per step + overlaps with backward compute → tolerates higher latency → can span nodes
- PP only sends activations between adjacent stages → minimal total volume, latency-tolerant → outermost, can span multiple network hops
By placing TP innermost, consecutive rank IDs map to GPUs on the same node connected by NVLink. PP outermost means pipeline stages span across nodes, which is fine because PP communication is infrequent and small.